 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperOffload: Graph-Driven Hierarchical Memory Management for Large Language Models on SuperNode Architectures
Feb 03, 2026The rapid evolution of Large Language Models (LLMs) towards long-context reasoning and sparse architectures has pushed memory requirements far beyond the capacity of individual device HBM. While emerging supernode architectures offer terabyte-scale shared memory pools via high-bandwidth interconnects, existing software stacks fail to exploit this hardware effectively. Current runtime-based offloading and swapping techniques operate with a local view, leading to reactive scheduling and exposed communication latency that stall the computation pipeline. In this paper, we propose the SuperNode Memory Management Framework (\textbf{HyperOffload}). It employs a compiler-assisted approach that leverages graph-driven memory management to treat remote memory access as explicit operations in the computation graph, specifically designed for hierarchical SuperNode architectures. Unlike reactive runtime systems, SuperNode represents data movement using cache operators within the compiler's Intermediate Representation (IR). This design enables a global, compile-time analysis of tensor lifetimes and execution dependencies. Leveraging this visibility, we develop a global execution-order refinement algorithm that statically schedules data transfers to hide remote memory latency behind compute-intensive regions. We implement SuperNode within the production deep learning framework MindSpore, adding a remote memory backend and specialized compiler passes. Evaluation on representative LLM workloads shows that SuperNode reduces peak device memory usage by up to 26\% for inference while maintaining end-to-end performance. Our work demonstrates that integrating memory-augmented hardware into the compiler's optimization framework is essential for scaling next-generation AI workloads.
AKG kernel Agent: A Multi-Agent Framework for Cross-Platform Kernel Synthesis
Dec 29, 2025Modern AI models demand high-performance computation kernels. The growing complexity of LLMs, multimodal architectures, and recommendation systems, combined with techniques like sparsity and quantization, creates significant computational challenges. Moreover, frequent hardware updates and diverse chip architectures further complicate this landscape, requiring tailored kernel implementations for each platform. However, manual optimization cannot keep pace with these demands, creating a critical bottleneck in AI system development. Recent advances in LLM code generation capabilities have opened new possibilities for automating kernel development. In this work, we propose AKG kernel agent (AI-driven Kernel Generator), a multi-agent system that automates kernel generation, migration, and performance tuning. AKG kernel agent is designed to support multiple domain-specific languages (DSLs), including Triton, TileLang, CPP, and CUDA-C, enabling it to target different hardware backends while maintaining correctness and portability. The system's modular design allows rapid integration of new DSLs and hardware targets. When evaluated on KernelBench using Triton DSL across GPU and NPU backends, AKG kernel agent achieves an average speedup of 1.46$\times$ over PyTorch Eager baselines implementations, demonstrating its effectiveness in accelerating kernel development for modern AI workloads.
Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security
Jan 10, 2024



Since the advent of personal computing devices, intelligent personal assistants (IPAs) have been one of the key technologies that researchers and engineers have focused on, aiming to help users efficiently obtain information and execute tasks, and provide users with more intelligent, convenient, and rich interaction experiences. With the development of smartphones and IoT, computing and sensing devices have become ubiquitous, greatly expanding the boundaries of IPAs. However, due to the lack of capabilities such as user intent understanding, task planning, tool using, and personal data management etc., existing IPAs still have limited practicality and scalability. Recently, the emergence of foundation models, represented by large language models (LLMs), brings new opportunities for the development of IPAs. With the powerful semantic understanding and reasoning capabilities, LLM can enable intelligent agents to solve complex problems autonomously. In this paper, we focus on Personal LLM Agents, which are LLM-based agents that are deeply integrated with personal data and personal devices and used for personal assistance. We envision that Personal LLM Agents will become a major software paradigm for end-users in the upcoming era. To realize this vision, we take the first step to discuss several important questions about Personal LLM Agents, including their architecture, capability, efficiency and security. We start by summarizing the key components and design choices in the architecture of Personal LLM Agents, followed by an in-depth analysis of the opinions collected from domain experts. Next, we discuss several key challenges to achieve intelligent, efficient and secure Personal LLM Agents, followed by a comprehensive survey of representative solutions to address these challenges.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021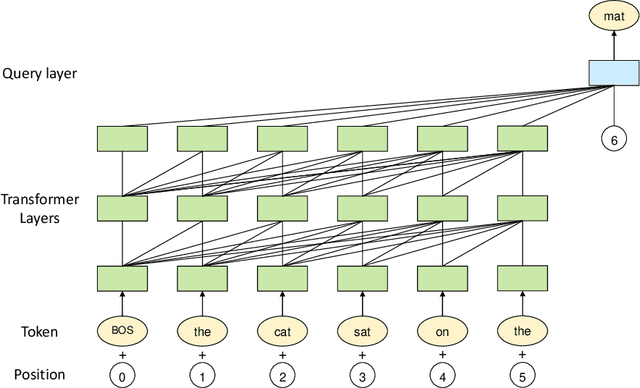
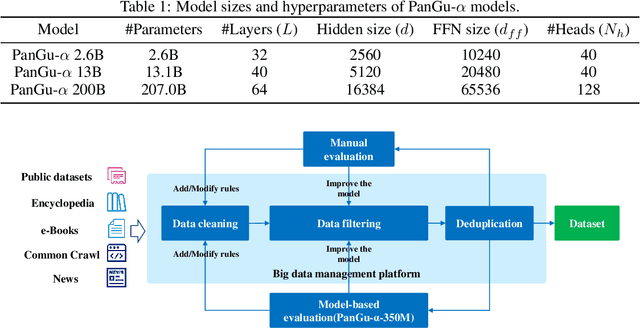
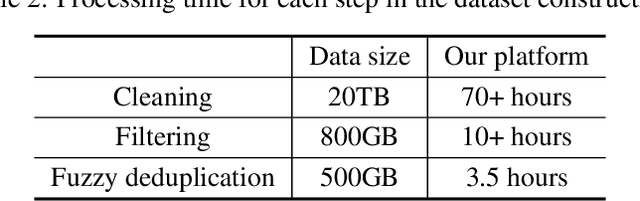
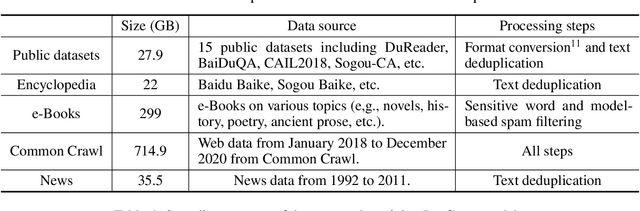
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.